Matrix Factorization
本文将通过一个详细的例子分析矩阵分解思想及其在推荐系统上的应用
Introduction
接下来介绍矩阵分解的思想:有时候存在两种object,它们之间会受到某种共同潜在因素(latent factor)的操控,如果我们找出这些潜在因素,就可以对用户的行为进行预测,这也是推荐系统常用的方法之一
假设我们现在去调查每个人购买的公仔数目,ABCDE代表5个人,每个人或者每个公仔实际上都是有着傲娇的属性或天然呆的属性
我们可以用vector去描述人和公仔的属性,如果某个人的属性和某个公仔的属性是match的,即他们背后的vector很像(内积值很大),这个人就会偏向于拥有更多这种类型的公仔
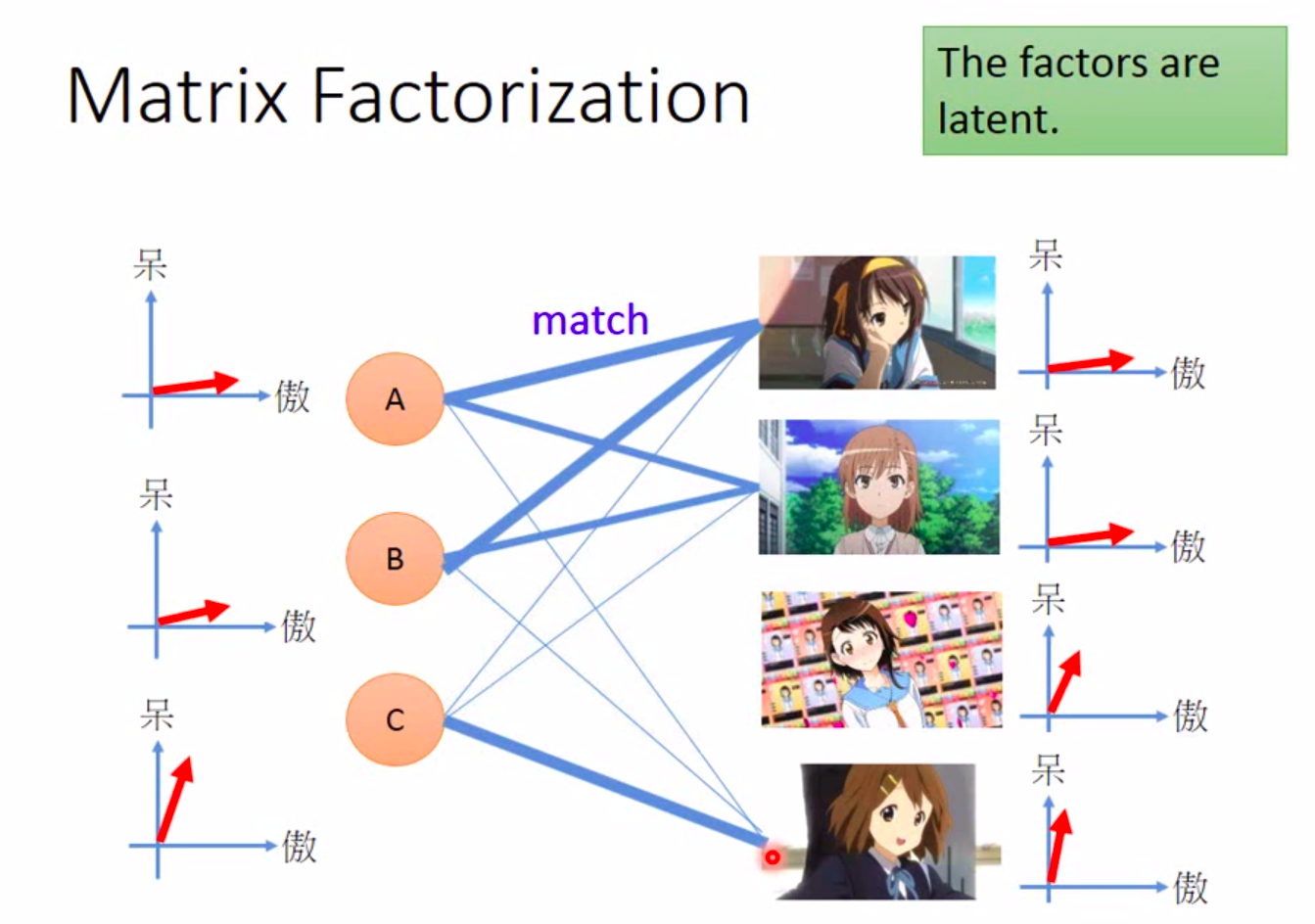
matrix expression
但是,我们没有办法直接观察某个人背后这些潜在的属性,也不会有人在意一个肥宅心里想的是什么,我们同样也没有办法直接得到动漫人物背后的属性;我们目前有的,只是动漫人物和人之间的关系,即每个人已购买的公仔数目,我们要通过这个关系去推测出动漫人物与人背后的潜在因素(latent factor)
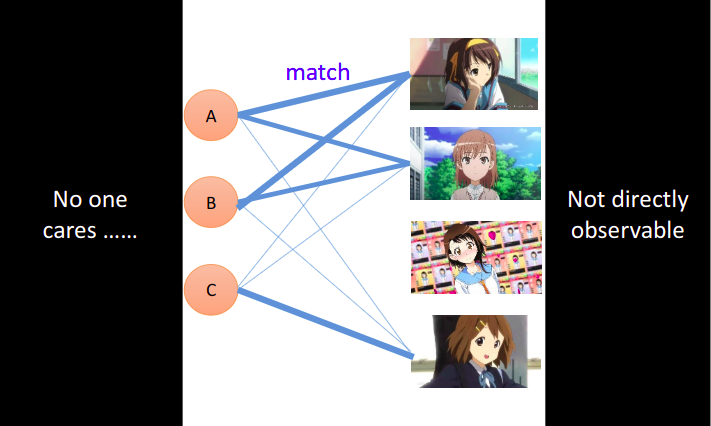
我们可以把每个人的属性用vector
做一个假设:matrix
比如,
接下来就用下图所示的矩阵相乘的方式来表示这样的关系,其中
我们要找一组

prediction
但有时候,部分的information可能是会missing的,这时候就难以用SVD精确描述,但我们可以使用梯度下降的方法求解,loss function如下:
其中

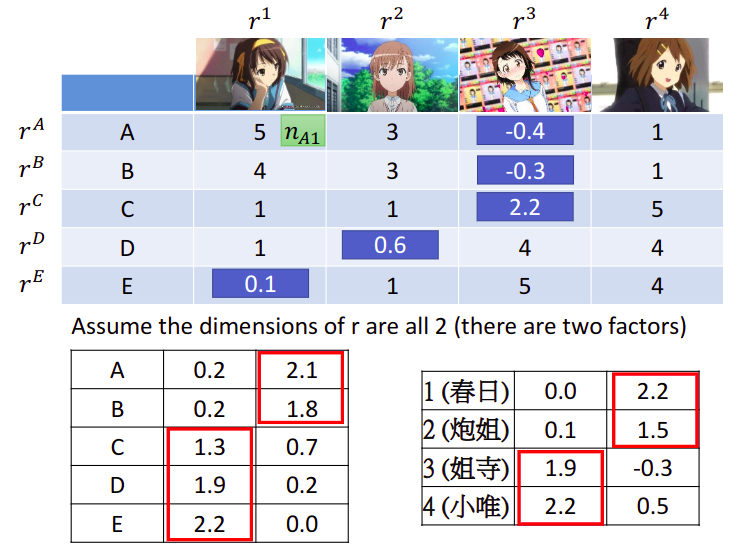
假设latent factor的数目等于2,则人的属性
人:A、B属于同一组属性,C、D、E属于同一组属性
动漫角色:1、2属于同一组属性,3、4属于同一组属性
结合动漫角色,可以分析出动漫角色的第一个维度是天然呆属性,第二个维度是傲娇属性
接下来就可以预测未知的值,只需要将人和动漫角色的vector做内积即可
这也是推荐系统的常用方法
more about matrix factorization
实际上除了人和动漫角色的属性之外,可能还存在其他因素操控购买数量这一数值,因此我们可以将式子更精确地改写为:
其中
当然你也可以加上一些regularization去对结果做约束
有关Matrix Factorization和推荐系统更多内容的介绍,可以参考paper(公众号回复“推荐系统”获取pdf ):Matrix Factorization Techniques For Recommender Systems
for Topic Analysis
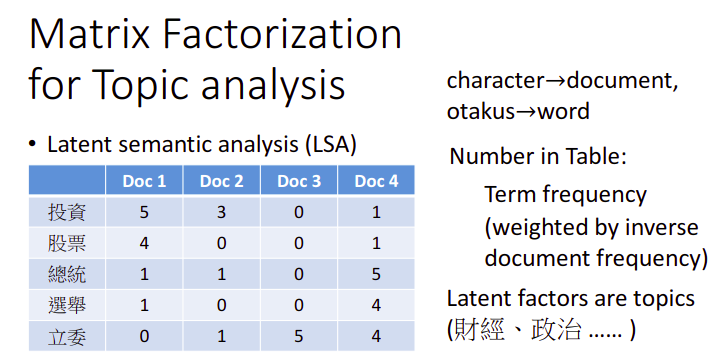
如果把matrix factorization的方法用在topic analysis上,就叫做LSA(Latent semantic analysis),潜在语义分析
我们只需要把动漫人物换成文章,人换成词汇,表中的值从购买数量换成词频即可,我们可以用词汇的重要性给词频加权,在各种文章中出现次数越多的词汇越不重要,出现次数越少则越重要
这个场景下找出的latent factor可能会是主题(topic),比如某个词汇或某个文档有多少比例是偏向于财经主题、政治主题...