DPO
Direct Preference Optimization: Your Language Model is Secretly a Reward Model
- Paper: https://arxiv.org/abs/2305.18290
- Code: https://github.com/eric-mitchell/direct-preference-optimization
1.简介
基于 人类反馈的强化学习(RLHF) 是一个复杂且不稳定的过程,拟合一个反映人类偏好的奖励模型,然后使用强化学习对大语言模型进行微调,以最大限度地提高估计奖励,同时又不能偏离原始模型太远。这涉及训练多个 LM,并在训练循环中从 LM 采样,从而产生大量的计算成本。
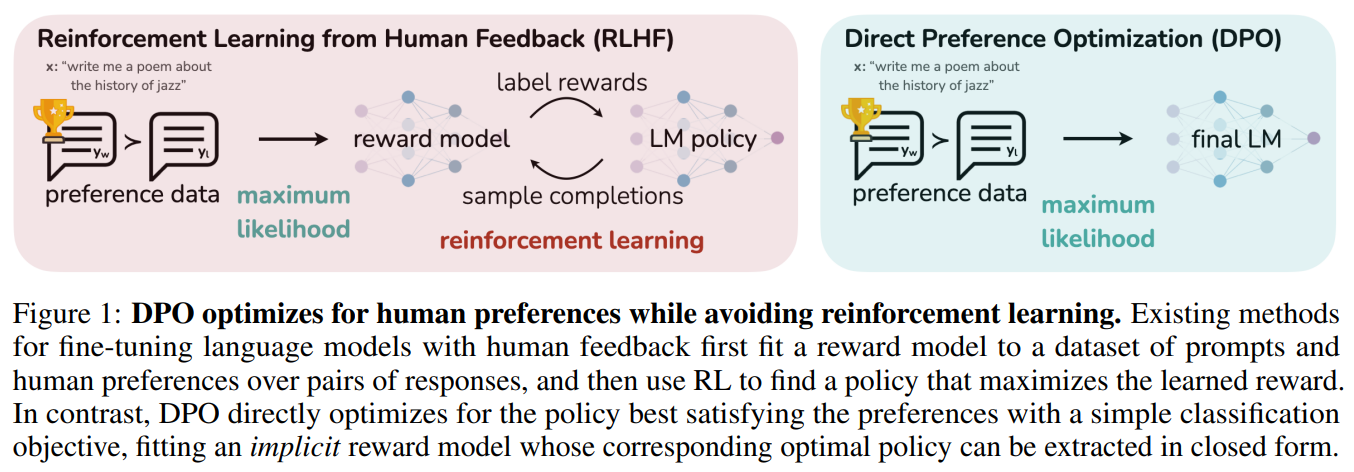
本文作者提出了 直接偏好优化(DPO) 算法,它稳定、高效且计算量轻,无需拟合奖励模型,也无需在微调期间从LM采样或执行显著的超参数调整。
实验表明,DPO 可以微调 LMs,使其与人类偏好保持一致,与现有方法一样或更好。值得注意的是,DPO 在情绪控制的能力上超越了 RLHF,提高了总结和单轮对话的响应质量,同时大大简化了实现和训练。
2.RLHF pipeline
RLHF通常由3个阶段组成:
- 监督微调 (SFT):高质量数据集上通过监督学习
- 偏好采样和奖励学习 (RM):标注排序的判别式标注成本远远低于生成答案的生成式标注。
- 强化学习微调 (PPO):在对SFT模型进行微调时生成的答案分布也会发生变化,会导致RM模型的评分会有偏差,需要用到强化学习.
2.1 SFT 阶段
RLHF 通常从一个通用的预训练 LM 开始,该 LM 在高质量数据集上通过监督学习(最大似然)对感兴趣的下游任务(如对话、指令跟随、总结等)进行微调,以获得模型
2.2 Reward 建模阶段
在第二阶段,用
通过静态数据集
其中 sigmoid 函数。奖励模型
2.3 RL 微调阶段
在 RL 阶段,使用学习到的奖励函数来对语言模型进行打分。特别是,制定了以下优化问题:
其中
由于语言生成的离散性,这个目标是不可微的,并且通常使用强化学习进行优化。标准方法是构造奖励函数
3.直接偏好优化(DPO)
与之前的 RLHF 方法不同,DPO 绕过了奖励建模步骤,并使用偏好数据直接优化语言模型。
3.1 PPO算法总览
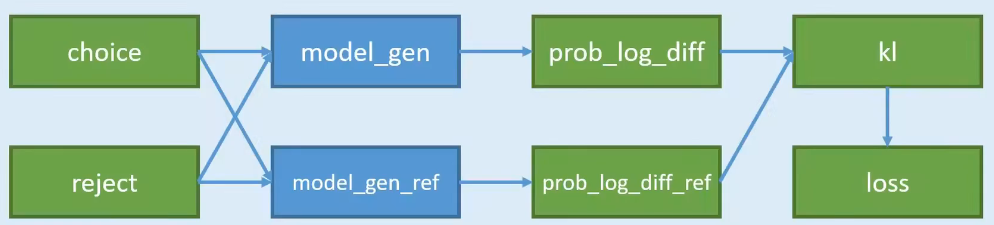
- 对一个问题,有两个回答 choice 和 reject,不是一个一定正确,一个一定不正确;而是训练出的语言模型,更加prefer哪一种,即希望语言模型以哪一种方式来回答。
- 准备两个模型 model_gen 和 model_gen_ref,其实是一摸一样的模型,只不过在训练过程中,只会训练其中一个,另外一个是不训练的。
- 把两两份数据,分别输入到两个模型中计算,可以得到4份概率;
- 4份数据中,其中有2份是想要的,2份是不想要的;2份想要的做差,得到
pro_log_diff,2份不想要的做差pro_log_diff_ref - 拿2份做差的数据,计算KL散度;惩罚policy模型对正样本概率的下降和负样本概率的上升
- 以KL散度计算Loss
3.1 DPO 目标函数
类似于奖励建模方法,策略目标变为:(推导过程详见原论文)
通过这种方式,绕过了显式奖励建模步骤,同时也避免了执行强化学习优化的需要。
逐步分析这个优化目标:首先,
- 对于人类偏好结果
,我们期望 越大越好; - 对于人类非偏好结果
,我们期望 越小越好。 - 如果
比较小,说明参考模型 没有正确分类该偏好响应 ,此时 的奖励系数很大。 - 如果
比较大,说明参考模型 没有正确分类该非偏好响应 ,此时 的奖励系数很大
3.2 DPO outline
- 对于每个prompt
,从参考策略中采样补全 ,用人类偏好进行标记以构建离线偏好数据集 。 - 对于给定的$ \pi_{\mathrm{ref}} $、
和 ,优化语言模型 以最小化 。
由于偏好数据集使用
该过程有助于缓解真实 \pi _{\mathrm{ref}}与 DPO 使用的
4.实验
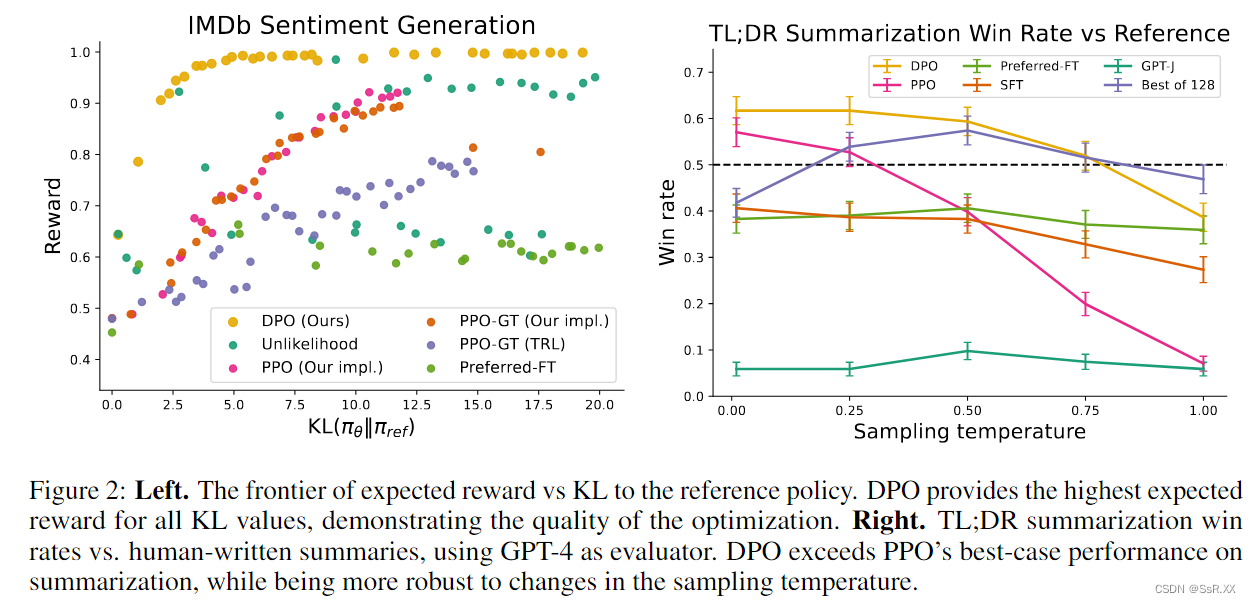
- 最大化奖励的同时最小化 KL 散度。可以看到 DPO 在保持较小 KL 散度时,也能够达到最大奖励。而 PPO 随着奖励的增大,KL 散度也在增大。
- 对不同采样温度的鲁棒性。DPO 在不同的采样温度下全面优于 PPO,同时在 Best of N 基线的最佳温度下也更胜一筹。
5.结论
基于人类反馈的强化学习(RLHF)是一个复杂且不稳定的过程,首先拟合一个反映人类偏好的奖励模型,然后使用强化学习对大语言模型进行微调,以最大限度地提高估计奖励,同时又不能偏离原始模型太远。这涉及训练多个 LM,并在训练循环中从 LM 采样,从而产生大量的计算成本。本文作者提出了直接偏好优化(DPO)算法,它稳定、高效且计算量轻,无需拟合奖励模型,也无需在微调期间从LM采样或执行显著的超参数调整。实验表明,DPO 可以微调 LMs,使其与人类偏好保持一致,与现有方法一样或更好。值得注意的是,DPO 在情绪控制的能力上超越了 RLHF,提高了总结和单轮对话的响应质量,同时大大简化了实现和训练。