SVG笔记(一):Python如何解析SVG?
Author: [麟十一]
Link: [https://mp.weixin.qq.com/s/6Be7RijyfwY2vTuOVGudDw]
写在前面
这一篇就是SVG里都有什么的“Python配套教程”了阅读之前可以先点击上一篇了解一下SVG的基本概念以及<path>标签中的属性和命令。本文分为两个部分,第一部分使用四种方法解析SVG并提取出SVG中的 <path>路径,第二部分解析<path>路径,从路径中提取出点并进行图形复现 。 在日常工作中,解析SVG常常不是为了看文件结构,而是为了从中提取出想要的内容从而实现后面的操作,毕竟SVG的结构和内容在编辑器中一目了然。所以个人看法,解析的重点并不是解析本身,而是解析之后的结果 ,这也是本文第二部分所展示的内容:提取路径之后进行图形复现再说一句,如果只是在两三个文件中提取,记事本足够了,但如果在几千个文件中进行操作,编程才是最好的方法。 我使用的环境是Windows10+Python3.7 ,不同Python库所要求的具体Python版本在后文会有说明。
**1. 解析SVG
在上一篇中我们提到过SVG的概念,复习一下:SVG(Scalable Vector Graphics)是一种 可以绘制二维矢量图的XML语言,它由矢量形状、图片和文本3种对象构成。而XML(EXtensible Markup Language) 是一种标记电子文件使其具有结构性的语言**,XML常被用来标记、传输和存储数据。 由于SVG基于XML语法,所以使用解析XML的方法解析SVG是可行的,Python中有三种方法可以解析XML,分别为DOM ,ElementTree 和SAX ,Python中还有一个专门针对SVG<path>路径进行解析的库叫做svgpathtools 。下面会一一介绍这四种方法,还会对四种方法进行比较 。 1.1 需要的Python库 本文需要用到两个Python库:xml 和svgpathtools 。xml为Python标准库 ,不需要pip安装就可以直接使用,svgpathtools需要Python >=3.6。 1.2 使用的SVG 展示一下本篇会用到的示例SVG代码:
<svg version="1.1" viewBox="0 0 320 320" xmlns="http://www.w3.org/2000/svg">
<title>ma</title>
<g transform="scale(0.3, -0.3) translate(0, -900)">
<path d="M 600 396 Q 628 508 642 590 Q 656 672 680 694 Q 704 716 678 734 Q 652 752 628 764 Q 604 776 574 760 Q 544 744 486 732 Q 428 720 372 716 Q 316 712 280 712 Q 248 712 282 688 Q 316 664 360 674 Q 404 684 490 700 Q 576 716 590 710 Q 604 704 598 646 Q 592 588 580 536 Q 568 484 558 460 Q 548 436 568 392 C 579 364 593 367 600 396 Z"></path>
<path fill="lightblue" d="M 568 392 Q 400 372 370 368 Q 340 364 336 376 Q 372 540 384 556 Q 396 572 378 592 Q 360 612 326 624 Q 292 636 306 604 Q 320 572 316 514 Q 312 456 300 418 Q 288 380 276 372 Q 264 364 286 328 Q 308 292 328 310 Q 348 328 396 338 Q 444 348 552 362 Q 660 376 714 378 Q 768 380 778 364 Q 788 348 790 296 Q 792 244 776 152 Q 760 60 738 40 Q 716 20 652 48 Q 588 76 636 28 Q 684 -20 688 -58 Q 692 -96 742 -62 Q 792 -28 812 26 Q 832 80 842 178 Q 852 276 860 300 Q 868 324 880 344 Q 892 364 868 382 Q 844 400 810 418 Q 776 436 752 422 Q 728 408 600 396 L 568 392 Z"></path>
<path stroke="red" fill="pink" d="M 368 204 Q 204 180 148 182 Q 92 184 132 156 Q 172 128 222 140 Q 272 152 412 170 Q 552 188 624 190 Q 696 192 682 212 Q 668 232 638 244 Q 608 256 570 244 Q 532 232 368 204 Z"></path>
</g>
</svg>图形是这样子的: 矢量图示例 是的,我是专门设置成这个样子的简单介绍一下文件结构:根节点为**< svg>,根节点下有两个子节点,分别为
矢量图示例 是的,我是专门设置成这个样子的简单介绍一下文件结构:根节点为**< svg>,根节点下有两个子节点,分别为<title>和< g>,<title>中有一段文本ma ,<g>节点下有三个< path>**节点,分别代表马的三条笔画的路径。节点中包含了不同的属性,<g>中的属性transform是将画布进行了一个缩放和翻转,三个<path>分别含有d属性,d和fill属性,d、fill和stroke属性。 在上图中可以发现,第一笔(黑色)被第二笔(蓝色)遮住了一点,上一篇我们提到过,三个<path>很像三个图层,如果有填充色的话,后面的路径会遮住前面的路径。
1.3 DOM(Document Object Model) 第一个方法是文档对象模型(DOM) ,它是一种处理可拓展标记语言(XML)的标准编程接口(API)。DOM会将XML解析为一个树 ,通过对树的操作来对XML进行操作。DOM在解析XML文档时,会一次性读取整个文档并放入存储器中进行处理 ,所以说如果XML文件比较大,那么解析时占用的内存会比较多,速度也会比较慢。 来看一下树形结构的SVG长什么样子: 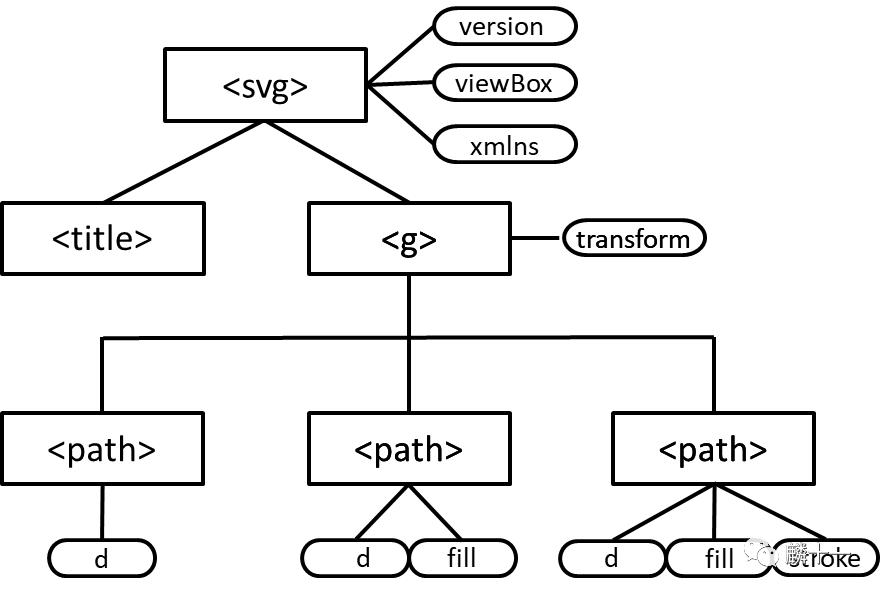 SVG转换成树形结构 接下来开始解析SVG,首先解析文件并提取所有节点 :
SVG转换成树形结构 接下来开始解析SVG,首先解析文件并提取所有节点 :
import xml.dom.minidom
#1.解析文件
svg_file = xml.dom.minidom.parse('马.svg')
print(svg_file)
#2.提取根节点
root = svg_file.documentElement
print(root)
#3.返回所有子节点
root.childNodes
#4.根据节点名称提取节点
#4.1 根节点提取title
title = root.getElementsByTagName('title')
print(title)
#4.2 根节点提取g
g = root.getElementsByTagName('g')
print(g)
#4.3 根节点提取path
path = root.getElementsByTagName('path')
print(path)
#4.4 title节点提取path
title[0].getElementsByTagName('path')
#4.5 g节点提取path
g[0].getElementsByTagName('path')第4部分使用getElementsByTagName函数根据节点名称提取节点,从根节点可以提取所有的节点,但是子节点只能提取自己节点下的所有节点 ,例如title节点不可以提取g节点下的path节点。 这里需要注意,getElementsByTagName函数返回的是一个列表 ,所以4.4和4.5使用了title[0]和g[0]将两个DOM元素先从列表中提取出来,才能正确调用函数。代码结果如下:
#1.解析文件
<xml.dom.minidom.Document object at 0x0000027C370B6888>
#2.提取根节点
<DOM Element: svg at 0x27c36bf79c8>
#3.返回所有子节点列表
[<DOM Text node "'\n '">,
<DOM Element: title at 0x27c36fbeaf8>,
<DOM Text node "'\n '">,
<DOM Element: g at 0x27c36fbeb90>,
<DOM Text node "'\n'">]
#4.根据子节点名称提取子节点
#4.1 根节点提取title
[<DOM Element: title at 0x27c36fbeaf8>]
#4.2 根节点提取g
[<DOM Element: g at 0x27c36fbeb90>]
#4.3 根节点提取path
[<DOM Element: path at 0x27c36fbec28>,
<DOM Element: path at 0x27c36fbecc0>,
<DOM Element: path at 0x27c36fbed58>]
#4.4 title节点提取path
[]
#4.5 g节点提取path
[<DOM Element: path at 0x27c36fbec28>,
<DOM Element: path at 0x27c36fbecc0>,
<DOM Element: path at 0x27c36fbed58>]SVG文件解析的结果是一个对象,每一个节点被提取后是一个DOM元素** 。第3部分使用childNodes函数返回标签对<svg></svg>之间的所有内容,从结果中可以看到,函数返回的是一个列表,除去节点元素,所有换行符 '\n' 也被当作文本节点一并返回了。 前文已经说过,子节点只能提取自己节点下的数据,无法提取其它节点下的内容。所以4.4的结果是空 ,title节点无法提取g节点下的path节点。 接下来提取文本和属性 :
#5.提取标签对之间的文本数据
title[0].childNodes #5.1
title[0].firstChild #5.2
title[0].childNodes[0].nodeValue #5.3
title[0].firstChild.data #5.4
#6.提取属性
root.attributes['version'].value #6.1
root.getAttribute('version') #6.2第5部分5.1中childNodes函数返回节点中所有数据的列表,5.2中firstChild函数返回节点数据列表中的第一个元素 。5.3和5.4是等价的,nodeValue和data函数都可以从DOM元素中提取文本数据 。 第6部分6.1和6.2也是等价的,都是提取节点中的属性值,上面代码从根节点提取属性version的值。结果如下:
#5.提取标签对之间的文本数据
[<DOM Text node "'ma'">] #5.1
<DOM Text node "'ma'"> #5.2
'ma' #5.3
'ma' #5.4
#6.提取属性
'1.1' #6.1
'1.1' #6.2代码结果很简单,不再做过多解释。接下来从g节点属性d中提取每一条路径的“参数+命令”字符串 ,这也是为了本文第二部分复现图形做准备。
#7.提取属性d的值进行存储
d_string = []
for i in path:
d_string.append(i.getAttribute('d'))
print(d_string)代码使用getAttribute提取属性值,结果如下:
#7.提取属性d的值进行存储
['M 600 396 Q 628 508 642 590 Q 656 672 680 694 Q 704 716 678 734 Q 652 752 628 764 Q 604 776 574 760 Q 544 744 486 732 Q 428 720 372 716 Q 316 712 280 712 Q 248 712 282 688 Q 316 664 360 674 Q 404 684 490 700 Q 576 716 590 710 Q 604 704 598 646 Q 592 588 580 536 Q 568 484 558 460 Q 548 436 568 392 C 579 364 593 367 600 396 Z',
'M 568 392 Q 400 372 370 368 Q 340 364 336 376 Q 372 540 384 556 Q 396 572 378 592 Q 360 612 326 624 Q 292 636 306 604 Q 320 572 316 514 Q 312 456 300 418 Q 288 380 276 372 Q 264 364 286 328 Q 308 292 328 310 Q 348 328 396 338 Q 444 348 552 362 Q 660 376 714 378 Q 768 380 778 364 Q 788 348 790 296 Q 792 244 776 152 Q 760 60 738 40 Q 716 20 652 48 Q 588 76 636 28 Q 684 -20 688 -58 Q 692 -96 742 -62 Q 792 -28 812 26 Q 832 80 842 178 Q 852 276 860 300 Q 868 324 880 344 Q 892 364 868 382 Q 844 400 810 418 Q 776 436 752 422 Q 728 408 600 396 L 568 392 Z',
'M 368 204 Q 204 180 148 182 Q 92 184 132 156 Q 172 128 222 140 Q 272 152 412 170 Q 552 188 624 190 Q 696 192 682 212 Q 668 232 638 244 Q 608 256 570 244 Q 532 232 368 204 Z']d_string 是一个列表,长度为3,按顺序存储了“马”中三个笔画的路径 。
1.4 ElementTreeElementTree(元素树)是一个轻量级的DOM ,可以被认为是第一种方法的简化版,它也拥有处理可拓展标记语言(XML)的API。之所以被称为轻量级DOM,因为它比DOM速度更快,消耗内存更少 。但是,在解析SVG的时候结果可能不是那么尽如人意。往下看吧 首先还是解析文件并提取所有节点 :
from xml.etree import ElementTree as ET
#1.解析文件
tree = ET.parse('马.svg')
print(tree)
#2.提取根节点
root = tree.getroot()
print(root) #2.1 打印根节点
print(root.tag) #2.2 打印根节点名称
#3.提取子节点
#3.1 子节点总数
print("根节点共有 {} 个子节点".format(len(root)))
#3.2 打印出每一层的节点
for i in range(len(root)):
print("节点{} : {}".format(i+1, root[i].tag))
print(" 节点{}拥有{}个子节点".format(i+1, len(root[i])))
if len(root[i]) > 0:
for j in range(len(root[i])):
print(" 子节点{} : {}".format(j+1, root[i][j]))ElementTree中使用tag函数提取节点名称。和DOM不同的是,ElementTree提取出的根节点是一个列表,里面存储着所有的子节点内容 ,所以在ElementTree中可以通过读取根节点列表的方式来获取所有节点。结果如下:
#1.解析文件
<xml.etree.ElementTree.ElementTree object at 0x0000023D8BE4ADC0>
#2.提取根节点
#2.1 打印根节点
<Element '{http://www.w3.org/2000/svg}svg' at 0x0000023D8BE5C9F0>
#2.2 打印根节点名称
{http://www.w3.org/2000/svg}svg
#3.返回所有子节点
#3.1 子节点总数
根节点共有 2 个子节点
#3.2 打印出每一层的节点
节点1 : {http://www.w3.org/2000/svg}title
节点1拥有0个子节点
节点2 : {http://www.w3.org/2000/svg}g
节点2拥有3个子节点
子节点1 : <Element '{http://www.w3.org/2000/svg}path' at 0x0000023D8D4684A0>
子节点2 : <Element '{http://www.w3.org/2000/svg}path' at 0x0000023D8D468770>
子节点3 : <Element '{http://www.w3.org/2000/svg}path' at 0x0000023D8D468540>从结果中可以发现,ElementTree把svg节点名称读取成了这个样子节点名称应该是svg,结果提取成了{http://www.w3.org/2000/svg}svg。多出来的那一段是svg节点中xmlns属性的内容,复习一下:xmlns="http://www.w3.org/2000/svg" 我修改了xmlns属性的位置也没有用,只有删除了之后才能正确提取出svg名称。但是没有了xmlns(命名空间)属性之后,SVG就显示不出图像了。所以,就这样吧 看来轻量级的DOM和原DOM相比还是有一些区别的。 另外,从结果里还能发现,root[0] 就是title节点,root[1] 就是g节点,root[1][0] 就是g节点中第一个path节点。接下来提取文本和属性 :
#4.提取标签对之间的文本数据
title = root[0] ;title.text #4.1
g = root[1] ; g.text #4.2
#5.提取属性
root.attrib #5.1
g[1].attrib['fill'] #5.2第4部分使用text函数提取文本,第5部分中5.1使用attrib函数返回节点中的属性名称和属性值,5.2通过输入属性名称来返回单个属性的值。结果如下:
#4.提取标签对之间的文本数据
'ma' #4.1
'\n ' #4.2
#5.提取属性
{'version': '1.1', 'viewBox': '0 0 320 320'} #5.1
'lightblue' #5.2第4部分中4.1提取出了title节点中的文本数据ma,由于g节点中并没有文本数据,所以取出来的只是换行符'\n'。第5部分5.1的结果中,xmlns属性并没有被正确提取出来,当然不能被提取出来,因为它已经被提取到了节点名称里 最后来提取d属性的值:
#6.提取属性d的值进行存储
d_string = []
for path in g:
d_string.append(path.attrib['d'])
d_string这部分的代码也很简单,不再做过多说明,提取出来的d_string结果也和DOM方法提取出的内容相同:
#6.提取属性d的值进行存储
['M 600 396 Q 628 508 642 590 Q 656 672 680 694 Q 704 716 678 734 Q 652 752 628 764 Q 604 776 574 760 Q 544 744 486 732 Q 428 720 372 716 Q 316 712 280 712 Q 248 712 282 688 Q 316 664 360 674 Q 404 684 490 700 Q 576 716 590 710 Q 604 704 598 646 Q 592 588 580 536 Q 568 484 558 460 Q 548 436 568 392 C 579 364 593 367 600 396 Z',
'M 568 392 Q 400 372 370 368 Q 340 364 336 376 Q 372 540 384 556 Q 396 572 378 592 Q 360 612 326 624 Q 292 636 306 604 Q 320 572 316 514 Q 312 456 300 418 Q 288 380 276 372 Q 264 364 286 328 Q 308 292 328 310 Q 348 328 396 338 Q 444 348 552 362 Q 660 376 714 378 Q 768 380 778 364 Q 788 348 790 296 Q 792 244 776 152 Q 760 60 738 40 Q 716 20 652 48 Q 588 76 636 28 Q 684 -20 688 -58 Q 692 -96 742 -62 Q 792 -28 812 26 Q 832 80 842 178 Q 852 276 860 300 Q 868 324 880 344 Q 892 364 868 382 Q 844 400 810 418 Q 776 436 752 422 Q 728 408 600 396 L 568 392 Z',
'M 368 204 Q 204 180 148 182 Q 92 184 132 156 Q 172 128 222 140 Q 272 152 412 170 Q 552 188 624 190 Q 696 192 682 212 Q 668 232 638 244 Q 608 256 570 244 Q 532 232 368 204 Z']1.5 SAX(Simple API for XML) 前面的两个方法都是基于对象 的,从前文的结果也能看到两个方法解析出的SVG文件都是对象。而SAX方法是基于事件 的,它会逐行扫描文档,在扫描的过程中通过触发一个一个事件并调用回调函数来处理XML文件 。 在SAX扫描XML文件的时候,每当识别出特定的内容,就会生成一个事件 。例如识别出节点开始标签(如<title>)时,会生成一个start事件,识别出节点结束标签(如</title>)时,会生成一个end事件。来看一张SAX处理SVG文件的过程示意图:  SAX解析XML文件过程 上图左边的一系列圆圈就是SAX生成的各种事件,可以看到有start,char和end三个事件。start代表“开始标记事件 ”,char代表“处理文本事件 ”,end代表“结束标记事件 ”。SAX中还可以触发其他事件,但在这里只展示三个最主要的事件。 以上图为例,当解析器遇到
SAX解析XML文件过程 上图左边的一系列圆圈就是SAX生成的各种事件,可以看到有start,char和end三个事件。start代表“开始标记事件 ”,char代表“处理文本事件 ”,end代表“结束标记事件 ”。SAX中还可以触发其他事件,但在这里只展示三个最主要的事件。 以上图为例,当解析器遇到<svg>标签时,生成第一个开始标记事件start1 ,之后遇到了第二个标签<title>生成start2 ,title节点中包括了文本数据'ma',所以解析器遇到文本数据之后会生成处理文本事件char ,文本处理结束之后,解析器遇到</title>标签生成结束标记事件end1 。以此类推,直到解析器遇到</svg>标签生成结束标记事件end6 结束解析。
在使用SAX解析XML时,需要输入两个参数:XML文件 和ContentHandler类 。这个类就包含了上面所说的各种处理事件的函数。来看一下代码:
import xml.sax
#创建SVGHandler类,继承ContentHandler类
class SVGHandler(xml.sax.ContentHandler):
def __init__(self):
self.data = '' #文本
self.node = '' #节点名称
# 遇到<tag>标签时执行的方法,这里重写原方法
# tag表示节点名称,attrs表示属性
def startElement(self, tag, attrs):
node_list = ['svg', 'title', 'g', 'path']
d_string = []
for node in node_list:
self.data = tag
if self.data == node:
print('=====' + node + '=====')
attrs_list = attrs.getNames()
for i in range(len(attrs_list)):
print(attrs_list[i] + ' : ' + attrs[attrs_list[i]])
#保存path路径
if self.data == 'path':
d_string.append(attrs['d'])
#将path路径写入TXT文档
with open('d_string.txt','w', encoding='utf-8') as f:
for i in range(len(d_string)):
f.write(d_string[i] + '\n')
#遇到<tag></tag>标签对之间的文本时执行的方法
#content代表文本数据
def characters(self, content):
#只有title节点中有文本数据
if self.data == 'title':
self.node = content
#新增方法,为了返回d_string
def output(self):
d_string = self.startElement(self, tag, attrs)
return d_string
#遇到</tag>标签时执行的方法
def endElement(self, tag):
self.data = tag
if self.data == 'title':
print('title = ' + self.node)
#调用类和函数
if __name__ == '__main__':
#创建XML解析文件
parser = xml.sax.make_parser()
#调用类和函数
handler = SVGHandler()
parser.setContentHandler(handler)
parser.parse('马.svg')上面的代码中我们创建了一个新的类SVGHandler,这个类继承了 ContentHandler 类并重写了函数。在这个类中我设置了四个函数,分别是 :startElement,characters,endElement 和 output。前三个函数分别对应事件开始,处理文本和事件结束,output是我新建的函数,由于我不知道怎么从类中取出d_string,所以只能把它输出成为一个TXT文件 SAX方法好处在于可以把所有的方法都写进类中,解析的时候操作会更简单,实例化类并调用函数就能得到所有的结果:
=====svg=====
version : 1.1
viewBox : 0 0 320 320
xmlns : http://www.w3.org/2000/svg
=====title=====
title = ma
=====g=====
transform : scale(0.3, -0.3) translate(0, -900)
=====path=====
d : M 600 396 Q 628 508 642 590 Q 656 672 680 694 Q 704 716 678 734 Q 652 752 628 764 Q 604 776 574 760 Q 544 744 486 732 Q 428 720 372 716 Q 316 712 280 712 Q 248 712 282 688 Q 316 664 360 674 Q 404 684 490 700 Q 576 716 590 710 Q 604 704 598 646 Q 592 588 580 536 Q 568 484 558 460 Q 548 436 568 392 C 579 364 593 367 600 396 Z
=====path=====
fill : lightblue
d : M 568 392 Q 400 372 370 368 Q 340 364 336 376 Q 372 540 384 556 Q 396 572 378 592 Q 360 612 326 624 Q 292 636 306 604 Q 320 572 316 514 Q 312 456 300 418 Q 288 380 276 372 Q 264 364 286 328 Q 308 292 328 310 Q 348 328 396 338 Q 444 348 552 362 Q 660 376 714 378 Q 768 380 778 364 Q 788 348 790 296 Q 792 244 776 152 Q 760 60 738 40 Q 716 20 652 48 Q 588 76 636 28 Q 684 -20 688 -58 Q 692 -96 742 -62 Q 792 -28 812 26 Q 832 80 842 178 Q 852 276 860 300 Q 868 324 880 344 Q 892 364 868 382 Q 844 400 810 418 Q 776 436 752 422 Q 728 408 600 396 L 568 392 Z
=====path=====
stroke : red
fill : pink
d : M 368 204 Q 204 180 148 182 Q 92 184 132 156 Q 172 128 222 140 Q 272 152 412 170 Q 552 188 624 190 Q 696 192 682 212 Q 668 232 638 244 Q 608 256 570 244 Q 532 232 368 204 Z1.6 svgpathtools 最后介绍的方法是专门解析SVG文件path属性中的内容 ,这个方法对于XML文件没有什么用。svgpathtools会将SVG文件转换为path对象列表 和包含path中属性的列表字典 。这个库中有两个函数可以使用:
#方法1 svg2paths
from svgpathtools import svg2paths
paths, attributes = svg2paths('马.svg')
paths[0] #1.1 显示第一条path路径
attributes #1.2 显示<path>中所有属性
#方法2 svg2paths2
from svgpathtools import svg2paths2
paths, attributes, svg_attributes = svg2paths2('马.svg')
svg_attributes #2.1 显示SVG文件属性上面的两种方法相差不多,svg2paths2函数会比svg2paths多返回一个列表字典,包含了SVG文件的属性 ,也就是svg节点中的属性名称和内容。结果如下:
#方法1 svg2paths
#1.1 显示第一条path路径
Path(QuadraticBezier(start=(600+396j), control=(628+508j), end=(642+590j)),
QuadraticBezier(start=(642+590j), control=(656+672j), end=(680+694j)),
QuadraticBezier(start=(680+694j), control=(704+716j), end=(678+734j)),
QuadraticBezier(start=(678+734j), control=(652+752j), end=(628+764j)),
QuadraticBezier(start=(628+764j), control=(604+776j), end=(574+760j)),
QuadraticBezier(start=(574+760j), control=(544+744j), end=(486+732j)),
QuadraticBezier(start=(486+732j), control=(428+720j), end=(372+716j)),
QuadraticBezier(start=(372+716j), control=(316+712j), end=(280+712j)),
QuadraticBezier(start=(280+712j), control=(248+712j), end=(282+688j)),
QuadraticBezier(start=(282+688j), control=(316+664j), end=(360+674j)),
QuadraticBezier(start=(360+674j), control=(404+684j), end=(490+700j)),
QuadraticBezier(start=(490+700j), control=(576+716j), end=(590+710j)),
QuadraticBezier(start=(590+710j), control=(604+704j), end=(598+646j)),
QuadraticBezier(start=(598+646j), control=(592+588j), end=(580+536j)),
QuadraticBezier(start=(580+536j), control=(568+484j), end=(558+460j)),
QuadraticBezier(start=(558+460j), control=(548+436j), end=(568+392j)),
CubicBezier(start=(568+392j), control1=(579+364j), control2=(593+367j), end=(600+396j)))
#1.2 显示<path>中所有属性
[{'d': 'M 600 396 Q 628 508 642 590 Q 656 672 680 694 Q 704 716 678 734 Q 652 752 628 764 Q 604 776 574 760 Q 544 744 486 732 Q 428 720 372 716 Q 316 712 280 712 Q 248 712 282 688 Q 316 664 360 674 Q 404 684 490 700 Q 576 716 590 710 Q 604 704 598 646 Q 592 588 580 536 Q 568 484 558 460 Q 548 436 568 392 C 579 364 593 367 600 396 Z'},
{'fill': 'lightblue',
'd': 'M 568 392 Q 400 372 370 368 Q 340 364 336 376 Q 372 540 384 556 Q 396 572 378 592 Q 360 612 326 624 Q 292 636 306 604 Q 320 572 316 514 Q 312 456 300 418 Q 288 380 276 372 Q 264 364 286 328 Q 308 292 328 310 Q 348 328 396 338 Q 444 348 552 362 Q 660 376 714 378 Q 768 380 778 364 Q 788 348 790 296 Q 792 244 776 152 Q 760 60 738 40 Q 716 20 652 48 Q 588 76 636 28 Q 684 -20 688 -58 Q 692 -96 742 -62 Q 792 -28 812 26 Q 832 80 842 178 Q 852 276 860 300 Q 868 324 880 344 Q 892 364 868 382 Q 844 400 810 418 Q 776 436 752 422 Q 728 408 600 396 L 568 392 Z'},
{'stroke': 'red',
'fill': 'pink',
'd': 'M 368 204 Q 204 180 148 182 Q 92 184 132 156 Q 172 128 222 140 Q 272 152 412 170 Q 552 188 624 190 Q 696 192 682 212 Q 668 232 638 244 Q 608 256 570 244 Q 532 232 368 204 Z'}]
#方法2 svg2paths2
#2.1 显示SVG文件属性
{'xmlns': 'http://www.w3.org/2000/svg',
'version': '1.1',
'viewBox': '0 0 320 320'}方法1中1.1 输出了**“马”字第一笔的所有曲线** ,共有16条二次贝塞尔曲线和1条三次贝塞尔曲线。1.2 结果是path节点中的列表字典,列表长度为3,代表“马”的三笔,每一笔都是一个字典,包含了属性名称和值。 方法2和方法1返回的paths和attributes结果是相同的,所以方法2只显示了svg_attributes的结果。最后提取d属性的值:
#3. 提取d属性的值并存储
d_string = []
for path in attributes:
d_string.append(path['d'])
d_string结果如下:
#3.提取属性d的值进行存储
['M 600 396 Q 628 508 642 590 Q 656 672 680 694 Q 704 716 678 734 Q 652 752 628 764 Q 604 776 574 760 Q 544 744 486 732 Q 428 720 372 716 Q 316 712 280 712 Q 248 712 282 688 Q 316 664 360 674 Q 404 684 490 700 Q 576 716 590 710 Q 604 704 598 646 Q 592 588 580 536 Q 568 484 558 460 Q 548 436 568 392 C 579 364 593 367 600 396 Z',
'M 568 392 Q 400 372 370 368 Q 340 364 336 376 Q 372 540 384 556 Q 396 572 378 592 Q 360 612 326 624 Q 292 636 306 604 Q 320 572 316 514 Q 312 456 300 418 Q 288 380 276 372 Q 264 364 286 328 Q 308 292 328 310 Q 348 328 396 338 Q 444 348 552 362 Q 660 376 714 378 Q 768 380 778 364 Q 788 348 790 296 Q 792 244 776 152 Q 760 60 738 40 Q 716 20 652 48 Q 588 76 636 28 Q 684 -20 688 -58 Q 692 -96 742 -62 Q 792 -28 812 26 Q 832 80 842 178 Q 852 276 860 300 Q 868 324 880 344 Q 892 364 868 382 Q 844 400 810 418 Q 776 436 752 422 Q 728 408 600 396 L 568 392 Z',
'M 368 204 Q 204 180 148 182 Q 92 184 132 156 Q 172 128 222 140 Q 272 152 412 170 Q 552 188 624 190 Q 696 192 682 212 Q 668 232 638 244 Q 608 256 570 244 Q 532 232 368 204 Z']1.7 总结与对比
最后对四种方法做一个小的总结和对比 DOM -- 基于对象 一次性读取所有XML文件,在内存中建立文件树 进行处理,XML文件大的时候占用内存大,处理速度慢 。由于树的结构已经被存储进了内存中,可以实现对于XML文件的随意读取与修改 。 ElementTree -- 基于对象 轻量级的DOM,同样将XML文件转换为树 进行处理,可以从生成的根节点列表中读取所有节点数据。相比DOM来说内存占用更少,速度更快 ,但是处理SVG文件的时候可能会有些差错 (上文节点名称提取错误)。 SAX -- 基于事件 SAX通过快速扫描XML文件对文件进行解析,遇到相应内容会触发事件进行处理。适合处理大型XML文件 ,相比DOM速度更快 。SAX方法需要定义ContentHandler类 ,这使得针对文件操作的自主性更强,但是需要设置的内容也更多。另外,SAX只能对XML文件进行读取,不能修改 。 svgpathtools 专门针对SVG文件中path节点 内容和属性进行解析,对于XML文件没有用。解析SVG非常方便。
2. 解析 <path>
终于写完了四种方法,这一部分来解析 <path>中的属性d。前面每种方法的最后,我都保存了一个叫d_string 的列表,里面存储了绘制“马”的**“命令+参数”** 字符串。
这里还是需要使用svgpathtools 库。有关这个库具体内容和操作方法,可以参考这个网站 _https://pypi.org/project/svgpathtools/_
import svgpathtools
#1.解析path路径
path_elements = []
for i in d_string:
path_elements.append(svgpathtools.parse_path(i))
print(path_elements[0])由于解析出的每一条路径内容都很长,所以这里只显示第1条路径 的解析结果:
#1.解析path路径
Path(QuadraticBezier(start=(600+396j), control=(628+508j), end=(642+590j)),
QuadraticBezier(start=(642+590j), control=(656+672j), end=(680+694j)),
QuadraticBezier(start=(680+694j), control=(704+716j), end=(678+734j)),
QuadraticBezier(start=(678+734j), control=(652+752j), end=(628+764j)),
QuadraticBezier(start=(628+764j), control=(604+776j), end=(574+760j)),
QuadraticBezier(start=(574+760j), control=(544+744j), end=(486+732j)),
QuadraticBezier(start=(486+732j), control=(428+720j), end=(372+716j)),
QuadraticBezier(start=(372+716j), control=(316+712j), end=(280+712j)),
QuadraticBezier(start=(280+712j), control=(248+712j), end=(282+688j)),
QuadraticBezier(start=(282+688j), control=(316+664j), end=(360+674j)),
QuadraticBezier(start=(360+674j), control=(404+684j), end=(490+700j)),
QuadraticBezier(start=(490+700j), control=(576+716j), end=(590+710j)),
QuadraticBezier(start=(590+710j), control=(604+704j), end=(598+646j)),
QuadraticBezier(start=(598+646j), control=(592+588j), end=(580+536j)),
QuadraticBezier(start=(580+536j), control=(568+484j), end=(558+460j)),
QuadraticBezier(start=(558+460j), control=(548+436j), end=(568+392j)),
CubicBezier(start=(568+392j), control1=(579+364j), control2=(593+367j), end=(600+396j)))这是组成**“马”第一笔** 的所有曲线:16条二次贝塞尔曲线和1条三次贝塞尔曲线,每一条曲线都包含了起点,控制点和终点,上一篇文中我们介绍过属性d中的绘制曲线命令,从上面的结果可以看出来,每一条曲线的终点,都是下一条曲线的起点 。最后一条三次贝塞尔曲线的终点就是第一条二次贝塞尔曲线的起点,因为只有这样图形才能形成一个闭环。
接下来以第一条二次贝塞尔曲线 为例,对具体的曲线进行解析:
from svgpathtools import Path
#2.解析第一条path中的第一条二次贝塞尔曲线
first_path = path_elements[0]
first_seg = first_path[0]
#2.1 打印第一条二次贝塞尔曲线
print(first_seg)
#2.2 打印第一条贝塞尔曲线“起点”
first_seg.start
#2.3 打印第一条贝塞尔曲线“控制点”
first_seg.control
#2.4 打印第一条贝塞尔曲线“终点”
first_seg.end
#2.5 打印第一条贝塞尔曲线“起点实部(x)”
first_seg.start.real
#2.6 打印第一条贝塞尔曲线“起点虚部(y)”
first_seg.start.imag
#2.7 打印第一条贝塞尔曲线“起点”
first_seg.point(0)
#2.8 打印第一条贝塞尔曲线“中点”
first_seg.point(0.5)
#2.9 打印第一条贝塞尔曲线“终点”
first_seg.point(1)上面的代码都是在打印第一条path路径中第一条二次贝塞尔曲线 的内容,2.2,2.3和2.4是使用start, control, end函数提取二次贝塞尔曲线的起点,控制点和终点。可以发现提取出来的全部都是虚数 ,实部代表x坐标,虚部代表y坐标 。2.5和2.6使用real和imag提取虚数的实部和虚部。
2.7,2.8和2.9需要说明一下,point函数可以在曲线上生成点 。point函数的参数在0-1 之间,0代表起点,1代表终点 ,相当于把这条线分成了无数份。2.8中输入了参数0.5 ,代表打印出曲线的中点 。如果输入0.25,那就是在曲线1/4处生成一个点。结果如下:
#2.解析第一条path中的第一条二次贝塞尔曲线
#2.1 打印第一条二次贝塞尔曲线
QuadraticBezier(start=(600+396j), control=(628+508j), end=(642+590j))
#2.2 打印第一条贝塞尔曲线“起点”
(600+396j)
#2.3 打印第一条贝塞尔曲线“控制点”
(628+508j)
#2.4 打印第一条贝塞尔曲线“终点”
(642+590j)
#2.5 打印第一条贝塞尔曲线“起点实部(x)”
600.0
#2.6 打印第一条贝塞尔曲线“起点虚部(y)”
396.0
#2.7 打印第一条贝塞尔曲线“起点”
(600+396j)
#2.8 打印第一条贝塞尔曲线“中点”
(624.5+500.5j)
#2.9 打印第一条贝塞尔曲线“终点”
(642+590j)只显示点的内容会有些抽象,下面用图形展示一下先展示“马”第一笔中17条曲线的起点 ,为了更清晰地展示这些点的关系,我用直线把这些点连了起来:
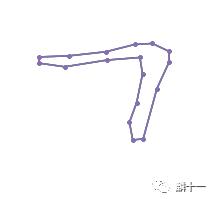 “马”第一笔—只有曲线起点
“马”第一笔—只有曲线起点
上图已经可以看出来第一笔的轮廓了但是还有些僵硬,当我们在每条曲线上增加了一个中点 (就是point(0.5) 生成的点)后画出来的图形是这样的:
 “马”第一笔—增加中点后
“马”第一笔—增加中点后
是不是看上去像是有曲线出没?其实连接每一点的线还是直线,但是整个笔画轮廓变得更加生动了生成的点越密集,图形就越形象 。
最后使用刚刚的方法复现一下整个SVG图形,还是先展示所有曲线起点连接成的图形:

“马”—只有曲线起点
在所有曲线之间生成一个中点之后再画出的图形如下:  “马”—增加中点后
“马”—增加中点后
以上就是解析SVG文件的所有内容,全文10500字,一不小心又写多了 下一篇继续讲SVG的内容:Python转换图片格式,下一篇见
~END~